l’IA générative
Qu’est-ce que l’IA générative ?
L’intelligence artificielle générative (IAGen) désigne une catégorie de techniques et de modèles d’intelligence artificielle qui créent un contenu nouveau et original à partir des données sur lesquelles les modèles ont été entraînés. Les résultats peuvent être des textes, des images ou des vidéos qui reflètent ou répondent à la requête. Autant les applications de l’intelligence artificielle peuvent s’étendre à de nombreux secteurs, l’IAGen peut également s’étendre à d’autres secteurs. Nombre de ces applications relèvent du domaine de l’art et de la créativité, car l’IAGen peut être utilisée pour créer des œuvres d’art, de la musique, des jeux vidéo et de la poésie sur la base des modèles observés dans les données d’apprentissage. Mais son apprentissage du langage le rend également apte à faciliter la communication, par exemple sous la forme de chatbots ou robots conversationnels ou d’agents conversationnels capables de simuler des conversations de type humain, la traduction linguistique, la synthèse vocale réaliste ou la synthèse de la parole à partir du texte. Il ne s’agit que de quelques exemples. Cet article aborde les façons dont l’IAGen offre à la fois des opportunités et des risques pour l’espace civique et la démocratie, et ce que les institutions gouvernementales, les organisations internationales, les activistes et les organisations de la société civile peuvent faire pour capitaliser sur les opportunités et se prémunir contre les risques.
Comment fonctionne l’IAGen ?
Au cœur de l’IAGen se trouvent les modèles génératifs, qui sont des algorithmes ou des architectures conçues pour apprendre les modèles et les statistiques sous-jacents des données d’apprentissage. Ces modèles peuvent ensuite utiliser ces connaissances acquises pour produire de nouveaux résultats qui ressemblent à la distribution des données d’origine. L’idée est de comprendre les modèles et les statistiques sous-jacents des données d’apprentissage de sorte à permettre au modèle de l’IA de générer de nouveaux échantillons appartenant à la même distribution.
Les étapes du processus l'IAGen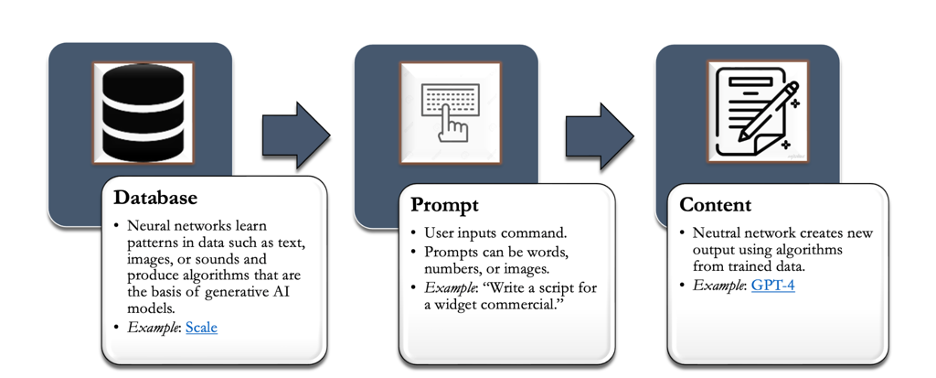
Comme l’illustre la figure ci-dessus, les modèles d’IAGen sont développés grâce à un processus dans lequel une base de données est utilisée pour former des réseaux neuronaux à l’aide de techniques d’apprentissage machine. Ces réseaux apprennent à identifier des modèles dans les données, ce qui leur permet de générer de nouveaux contenus ou de faire des prédictions sur la base des informations apprises. De là, les utilisateurs peuvent entrer des commandes sous forme de mots, de chiffres ou d’images dans ces modèles algorithmiques, et le modèle produit un contenu qui répondra en fonction de l’entrée et des modèles appris à partir des données d’apprentissage. Au fur et à mesure qu’ils sont entraînés sur des jeux de données de plus en plus vastes, les modèles d’IAGen acquièrent un éventail plus important de contenus possibles qu’ils peuvent générer sur différents supports, de l’audio aux images en passant par le textuel.
Jusqu’à récemment, l’IAGen se contentait d’imiter le style et la matière des données d’entrée. Par exemple, quelqu’un peut entrer un extrait de poème ou d’article de presse dans un modèle, et le modèle produit un poème ou un article de presse complet qui ressemble au contenu original. Dans le domaine de la linguistique, vous avez peut-être déjà vu un exemple de langage prédictif dans votre propre courrier électronique, comme le Smart Compose de Google, qui complète une phrase sur la base d’une combinaison des mots initiaux que vous utilisez et de l’attente probabiliste de ce qui pourrait suivre. Par exemple, une machine étudiant des milliards de mots à partir de jeux de données pourra générer une attente probabiliste d’une phrase commençant par « s’il vous plaît, venez ___». Dans 95 % des cas, la machine aurait pu voir « ici » comme le mot suivant, dans 3 % des cas « avec moi » et dans 2 % des cas « bientôt ». Ainsi, lorsqu’il complète des phrases ou génère des résultats, l’algorithme qui a appris la langue utilise la structure de la phrase et la combinaison de mots qu’il a vu précédemment. Les modèles étant probabilistes, ils peuvent parfois commettre des erreurs qui ne reflètent pas les intentions nuancées des données d’entrée.
L’IAGen dispose désormais de capacités bien plus étendues. Bien au-delà du texte, l’IAGen est aussi un outil de production d’images à partir de textes. Par exemple, des outils tels que DALL-E, Stable Diffusion et MidJourney permettent à l’utilisateur de saisir des descriptions textuelles que le modèle utilise ensuite pour produire une image correspondante. Ces images varient dans leur réalisme – par exemple, certaines semblent sortir d’une scène de science-fiction, d’autres ressemblent à une peinture et d’autres encore sont plus proches d’une photographie. En outre, il convient de noter que ces outils s’améliorent constamment, ce qui permet de repousser toujours plus loin les limites de ce qu’il est possible de réaliser avec la génération d’images à partir de texte.
Les modèles récents intègrent l’apprentissage machine à partir de modèles linguistiques, mais aussi d’informations factuelles sur la politique, la société et l’économie. Les modèles récents sont également capables de prendre des commandes d’entrée à partir d’images et de la voix, ce qui accroît encore leur polyvalence et leur utilité dans diverses applications.
Les modèles destinés aux consommateurs qui simulent une conversation humaine (« l’IA conversationnelle ») ont proliféré récemment et fonctionnent davantage comme des « robots conversationnels,», répondant à des requêtes et à des questions, à l’instar d’un moteur de recherche. Il peut s’agir par exemple de demander au modèle de répondre à l’une des questions suivantes :
- Parle de la capitale, de la forme de gouvernement ou du caractère du Kenya, ou encore de l’histoire de la décolonisation en Asie du Sud.
- Fournis une photo d’un dirigeant politique jouant d’un ukulélé dans le style de Salvador Dali.
- Écris et interprète une chanson sur l’adolescence qui imite une chanson de Drake.
En d’autres termes, ces modèles plus récents peuvent fonctionner comme un mélange entre une recherche Google et un échange avec une personne connaissant son domaine d’expertise. Tout comme un individu socialement attentif, ces modèles peuvent être enseignés au cours d’une conversation. Si vous posez une question sur les meilleurs restaurants de Manille et que le chatbot répond avec une liste de restaurants comprenant certains restaurants d’Europe continentale, vous pouvez alors effectuer un suivi et exprimer une préférence pour les restaurants philippins, ce qui incitera le chatbot à adapter sa sortie selon vos préférences spécifiques. Le modèle apprend en fonction des commentaires, bien que des modèles tels que ChatGPT souligneront rapidement qu’il n’est formé que sur des données jusqu’à une certaine date, ce qui signifie que certains restaurants auront fait faillite et que certains restaurants primés auront peut-être recadré. en haut. L’exemple met en évidence une tension fondamentale entre les modèles ou contenus à jour et la capacité d’affiner les modèles. Si nous essayons de faire en sorte que les modèles apprennent à partir des informations au fur et à mesure qu’elles sont produites, ces modèles généreront des réponses à jour mais ne seront pas en mesure de filtrer les résultats pour détecter les mauvaises informations, les discours de haine ou les théories du complot.

L’IAGen implique plusieurs concepts clés :
Modèles génératifs : Les modèles génératifs sont une classe de modèles d’apprentissage machine conçus pour créer ou générer de nouvelles données de sortie qui ressemblent à un jeu donné de données d’apprentissage. Ces modèles apprennent des modèles et des structures sous-jacents à partir des données d’apprentissage et utilisent ces connaissances pour générer de nouvelles données similaires.
ChatGPT : ChatGPT est un modèle de transformateur génératif pré-entraîné (GPT) développé par OpenAI. Bien que les chercheurs aient développé et utilisé des modèles linguistiques depuis des décennies, ChatGPT a été le premier modèle linguistique destiné aux consommateurs. Entraîné à comprendre et à produire des textes de type humain dans un contexte de dialogue, il a été spécialement conçu pour générer des réponses conversationnelles et s’engager dans des conversations interactives basées sur le texte. Il est donc bien adapté à la création de robots conversationnels, d’assistants virtuels et d’autres applications d’IA conversationnelle.
Réseau neuronal : Un réseau neuronal est un modèle informatique destiné à fonctionner comme les neurones interconnectés du cerveau. Il s’agit d’une partie importante de l’apprentissage profond car il effectue un calcul, et la force des connexions (poids) entre les neurones détermine le flux d’informations et influence la sortie.
Données d’apprentissage : Les données d’apprentissage sont les données utilisées pour entraîner les modèles génératifs. Ces données sont cruciales car le modèle apprend des modèles et des structures à partir de ces données pour créer de nouveaux contenus. Par exemple, dans le contexte de la production de textes, les données d’apprentissage consisteraient en une vaste collection de documents textuels, de phrases ou de paragraphes. La qualité et la diversité des données d’apprentissage ont un impact significatif sur la performance du modèle de l’IAGen car elles aident le modèle à générer un contenu plus pertinent.
Hallucination : Dans le contexte de l’IAGen, le terme « hallucination » désigne un phénomène par lequel le modèle d’IA produit des résultats qui ne sont pas fondés sur la réalité ou des représentations exactes des données d’entrée. En d’autres termes, l’IA génère un contenu qui semble exister, mais qui est en réalité entièrement fabriqué et ne repose pas sur les données réelles sur lesquelles elle a été entraînée. Par exemple, un modèle linguistique peut produire des paragraphes de texte qui semblent cohérents et factuels mais qui, après un examen plus approfondi, peuvent contenir de fausses informations, des événements qui ne se sont jamais produits ou des liens entre des concepts qui sont logiquement erronés. Le problème provient du bruit dans les données d’apprentissage. Le traitement et la réduction des hallucinations dans l’IAGen constituent un défi permanent pour la recherche. Les chercheurs et les développeurs s’efforcent d’améliorer la compréhension du contexte, de la cohérence et de l’exactitude factuelle des modèles afin de réduire la probabilité de générer un contenu pouvant être considéré comme hallucinatoire.
Invite : Une invite IAGen est une entrée ou une instruction spécifique donnée à un modèle IAGen pour le guider dans la production d’un résultat souhaité. Dans la génération d’images, une invite peut consister à spécifier le style, le contenu ou d’autres attributs de l’image générée. La qualité et la pertinence des résultats générés dépendent souvent de la clarté et de la spécificité de l’invite. Une invite bien conçue peut conduire à un contenu généré plus précis et plus souhaitable.
Mesures d’évaluation : L’évaluation de la qualité des résultats des modèles de l’IAGen peut s’avérer difficile, mais plusieurs mesures d’évaluation ont été développées pour évaluer divers aspects du contenu généré. Des mesures telles que Inception Score, Frechet Inception Distance (FID), and Perceptual Path Length (PPL) tentent de mesurer des aspects de la performance du modèle tels que la diversité des réponses (afin qu’elles ne ressemblent pas toutes à des copies les unes des autres), la pertinence (afin que les réponses soient en rapport avec le sujet) et la cohérence (afin que les réponses restent en rapport avec le sujet) du résultat.
Ingénierie de requête : L’ingénierie de requête est le processus de conception et d’amélioration des invites ou des instructions données aux systèmes d’IAGen, tels que les robots conversationnels ou les modèles de langage comme le GPT-3.5, afin d’obtenir des réponses spécifiques et souhaitées. Il s’agit d’élaborer le texte d’entrée ou la requête de manière à ce que le modèle génère des résultats qui correspondent à l’intention de l’utilisateur ou à la tâche voulue. Elle est utile pour optimiser les avantages de l’IAGen mais nécessite une compréhension approfondie du comportement et des capacités du modèle ainsi que des exigences spécifiques de l’application ou de la tâche. Des invites bien conçues peuvent améliorer l’expérience de l’utilisateur en garantissant que les modèles fournissent des réponses valables et précises.
En quoi l'IAGen est-elle pertinente à l'espace civique et à la démocratie ?
Le développement et la diffusion rapides des technologies de l’IAGen – dans les domaines de la médecine, de la durabilité environnementale, de la politique et du journalisme, entre autres – créent ou créeront d’énormes opportunités. L’IAGen sert en ce moment à faire des découvertes de médicaments, la conception de molécules, l’analyse de l’imagerie médicale et les recommandations de traitement personnalisé. Elle est utilisée pour modéliser et simuler les écosystèmes, prévoir les changements environnementaux et élaborer des stratégies de conservation. Elle offre des réponses plus accessibles sur les procédures administratives afin que les citoyens comprennent mieux leur gouvernement, un changement fondamental dans la manière dont les citoyens accèdent à l’information et dans le fonctionnement des gouvernements. Elle soutient la production de contenus écrits tels que des articles, des rapports et des publicités.
Dans tous ces secteurs, l’IAGen présente également des risques potentiels. Les gouvernements, en collaboration avec le secteur privé et les organisations de la société civile, adoptent des approches différentes pour trouver un équilibre entre la capitalisation des opportunités et la protection contre les risques, reflétant des philosophies différentes sur le risque et le rôle de l’innovation dans leurs économies respectives, ainsi que des précédents juridiques et des paysages politiques différents d’un pays à l’autre. Dans les pays où l’IA est utilisée intensivement, comme aux États-Unis ou dans les pays de l’Union européenne, ou dans les pays à forte intensité technologique comme la Chine, il existe un grand nombre d’initiatives pionnières. Les discussions sur la réglementation dans d’autres pays ont pris du retard. En Afrique, par exemple, les experts présents à la conférence Africa Tech Week au printemps 2023 se sont inquiétés du retard pris par l’Afrique en matière d’accès à l’IA et de la nécessité de rattraper ce retard pour profiter des avantages qu’offre l’IA dans l’économie, la médecine et la société, tout en évoquant les questions de protection de la vie privée et l’importance de la diversité dans les équipes de recherche sur l’IA pour éviter les préjugés. Ces conversations suggèrent que l’accès et la réglementation évoluent à des rythmes différents selon les contextes, et que les régions qui élaborent et testent actuellement des réglementations peuvent servir de modèles ou, du moins, fournir des enseignements à d’autres pays qui se mettent à jour.
L’Union européenne a rapidement réglementé l’IA en adoptant une approche fondée sur les risques qui interdit certains types « d’utilisations à haut risque». Les systèmes d’IAGen qui ne disposent pas de plans d’évaluation et d’atténuation des risques, d’informations claires pour les utilisateurs, de possibilités d’explication, d’enregistrement des activités et d’autres exigences, sont considérés comme présentant un risque élevé. Selon une étude réalisée. en 2021 par l’université de Stanford, la plupart des systèmes d’IAGen ne répondraient pas à ces normes. Toutefois, les dirigeants de 150 entreprises européennes se sont collectivement opposés à une réglementation agressive, suggérant qu’une réglementation trop stricte en matière d’IA inciterait les entreprises à établir leur siège social en dehors de l’Europe et étoufferait l’innovation et le développement économique dans la région. Une lettre ouverte reconnaît qu’une certaine réglementation peut être justifiée, mais que l’IAGen sera « décisive » et « puissante » et que « l’Europe ne peut pas se permettre de rester sur la touche ».
La Chine est l’un des pays les plus agressifs en matière de réglementation de l’IA. L’administration chinoise chargée de la cyber sécurité exige que l’IA soit transparente, impartiale et qu’elle ne soit pas utilisée pour générer de la mésinformation ou des troubles sociaux. Les règles existantes réglementent fortement les hypertrucages (médias synthétiques dans lesquels l’image d’une personne, y compris son visage et sa voix, est remplacée par l’image de quelqu’un d’autre, généralement à l’aide de l’IA). Tout fournisseur de services qui utilise du contenu produit par l’IAGen doit également obtenir le consentement des sujets d’hypertrucages, étiqueter les résultats, puis contrer toute mésinformation. Toutefois, l’adoption de telles réglementations ne signifie pas que les acteurs étatiques n’utiliseront pas l’IA à des fins malveillantes ou pour des opérations d’influence, comme nous l’expliquons ci-dessous.
Les États-Unis ont organisé un certain nombre d’auditions pour mieux comprendre la technologie et son impact sur la démocratie, mais en septembre 2023, ils n’avaient pas mis en place de législation significative pour réglementer l’IAGen. Mais, ils ont organisé un certain nombre d’auditions législatives afin de mieux comprendre la technologie et de se préparer à la réglementer. La Federal Trade Commission, chargée de promouvoir la protection des consommateurs, a adressé une lettre de 20 pages à OpenAI, le créateur de ChatGPT, pour lui demander de répondre à ses préoccupations en matière de protection de la vie privée et de sécurité des consommateurs. En outre, le gouvernement américain a collaboré avec les principales entreprises de l’IAGen pour établir des garanties volontaires de transparence et de sécurité à mesure que les risques et les avantages de la technologie évoluent.
Au-delà des initiatives réglementaires régionales ou nationales, le secrétaire général des Nations unies, António Guterrez, a plaidé en faveur de la transparence, de la redevabilité et de la surveillance de l’IA. M. Guterre a fait remarquer que « La communauté internationale réagit depuis longtemps aux nouvelles technologies susceptibles de perturber nos sociétés et nos économies. Nous nous sommes réunis aux Nations unies pour établir de nouvelles règles internationales, signer de nouveaux traités et créer de nouvelles agences mondiales. Si de nombreux pays ont préconisé différentes mesures et initiatives en matière de gouvernance de l’IA, une approche universelle s’impose ». La déclaration souligne le fait que l’espace numérique ne connaît pas de frontières et que les technologies logicielles innovées dans un pays seront inévitablement transférées dans d’autres, ce qui suggère que des normes ou des contraintes significatives sur l’IAGen nécessiteront probablement une approche internationale coordonnée. À cette fin, certains chercheurs ont proposé la création d’une organisation internationale de l’intelligence artificielle qui aiderait à certifier le respect des normes internationales en matière de sécurité en matière d’IA, tout en reconnaissant la nature intrinsèquement internationale du développement et du déploiement de l’IA.
Les opportunités
Améliorer la représentationL’un des principaux défis de la démocratie et de la société civile est de veiller à ce que les voix des électeurs soient entendues et représentées, ce qui implique en partie que les citoyens eux-mêmes participent au processus démocratique. L’IAGen peut être utile en donnant aux décideurs politiques et aux citoyens le moyen de communiquer plus efficacement et de renforcer la confiance dans les institutions. Une autre façon d’améliorer la représentativité est que l’IAGen fournisse des données qui permettent aux chercheurs et aux décideurs politiques de comprendre diverses questions sociales, économiques et environnementales, ainsi que les préoccupations des électeurs sur ces questions. Par exemple, l’IAGen pourrait servir à synthétiser d’importants volumes de commentaires provenant de lignes de commentaires ouvertes ou de courriels, afin de mieux comprendre les préoccupations de la base vers le haut des citoyens concernant leur démocratie. Certes, ces outils d’analyse de données doivent garantir la confidentialité des données, mais ils peuvent permettre aux responsables des institutions de visualiser les données et de comprendre ce qui intéresse les gens.
De nombreux règlements et textes législatifs sont compacts et difficiles à comprendre pour quiconque ne fait pas partie de la sphère de prise de décision. Ces problèmes d’accessibilité sont amplifiés pour les personnes en situation de handicaps tels que les déficiences cognitives. L’IAGen peut résumer de longs textes de loi et traduire des publications gouvernementales compactes dans un format facile à lire, avec des images et dans un langage simple. Les organisations de la société civile peuvent également utiliser l’IAGen pour développer des campagnes de médias sociaux et d’autres contenus afin de les rendre plus accessibles aux personnes en situation de handicap.
L’IAGen peut améliorer l’engagement civique en générant un contenu personnalisé adapté aux intérêts et aux préférences de chacun grâce à une combinaison d’analyse de données et d’apprentissage machine. Il peut s’agir de produire des documents d’information, des résumés d’actualité ou des visualisations qui attirent les citoyens et les encouragent à participer à des discussions et à des activités civiques. L’industrie du marketing a longtemps capitalisé sur le fait que le contenu spécifique aux consommateurs individuels est plus susceptible de susciter la consommation ou l’engagement, et l’idée est la même dans la société civile. Plus le contenu est personnalisé et ciblé sur une personne ou une catégorie de personnes, plus cette personne sera susceptible de répondre. Là encore, l’utilisation des données pour aider à classer les préférences des citoyens repose intrinsèquement sur les données des utilisateurs. Toutes les sociétés n’approuvent pas cette utilisation des données. Par exemple, l’Union européenne s’est montrée méfiante à l’égard de la protection de la vie privée, ce qui laisse à penser qu’il n’y aura pas de solution unique pour cette utilisation particulière de l’IAGen dans le cadre de l’engagement civique.
Cela dit, cet outil pourrait aider à lutter contre l’apathie des électeurs, qui peut conduire à une désaffection et à un désengagement vis-à-vis de la politique. Au lieu d’une communication passe-partout incitant les jeunes à voter, par exemple, l’IAGen pourrait produire un contenu intelligent connu pour trouver un écho auprès des jeunes femmes ou des groupes marginalisés, ce qui aiderait à surmonter certains des obstacles supplémentaires à l’engagement auxquels sont confrontés les groupes marginalisés. Dans un cadre éducatif, le contenu personnalisé pourrait être utilisé pour répondre aux besoins des étudiants de différentes régions et capacités d’apprentissage, tout en fournissant des tuteurs virtuels ou des outils d’apprentissage des langues.
Les robots conversationnels et les agents conversationnels alimentés par l’IAGen sont un autre moyen pour l’IAGen de favoriser la participation et la délibération du public. Ces outils peuvent faciliter la délibération publique en engageant le dialogue avec les citoyens, en répondant à leurs préoccupations et en les aidant à s’orienter par rapport à des questions civiques complexes. Ces agents peuvent fournir des informations, répondre aux questions et stimuler les discussions. Certaines municipalités ont déjà lancé des assistants virtuels et des robots conversationnels alimentés par l’IA qui automatisent les services civiques, en rationalisant les processus tels que les demandes de renseignements des citoyens, les demandes de services et les tâches administratives. Cela peut favoriser une efficacité et une réactivité accrues des opérations gouvernementales. Le manque de ressources municipales – par exemple de personnel – peut signifier que les citoyens ne disposent pas non plus des informations dont ils ont besoin pour participer de manière significative à la vie de leur société. Avec des ressources relativement limitées, un robot conversationnel peut être formé à partir de données locales afin de fournir les informations spécifiques nécessaires pour réduire cet écart.
Les robots conversationnels peuvent être formés en plusieurs langues, ce qui rend les informations et les ressources civiques plus accessibles à des populations diverses. Ils peuvent aider les personnes en situation de handicap en produisant des formats d’information alternatifs, tels que des descriptions audios ou des conversions texte-parole. L’IAGen peut être entraînée aux dialectes et aux langues locales, ce qui permet de promouvoir les cultures autochtones et de rendre le contenu numérique plus accessible aux diverses populations.
Il est important de noter que le déploiement de l’IAGen doit se faire en tenant compte des contextes locaux, des considérations culturelles et des préoccupations en matière de protection de la vie privée. L’adoption d’une approche de conception axée sur l’humain dans les collaborations entre les chercheurs en IA, les développeurs, les groupes de la société civile et les communautés locales peut contribuer à garantir que ces technologies sont adaptées de manière appropriée et équitable pour répondre aux besoins et aux défis spécifiques de la région.
L’IAGen peut également être utilisée pour l’analyse prédictive afin de prévoir les résultats potentiels des décisions politiques. Par exemple, les modèles génératifs alimentés par l’IA peuvent analyser les données pédologiques et météorologiques locales afin d’optimiser le rendement des cultures et de recommander des pratiques agricoles adaptées à des régions spécifiques. Elle peut servir à générer des simulations réalistes afin de prévoir les impacts potentiels et d’élaborer des stratégies de riposte aux catastrophes pour les opérations de secours. Elle peut analyser les conditions environnementales locales et la demande d’énergie afin d’optimiser le déploiement de sources d’énergie renouvelables telles que l’énergie solaire et l’énergie éolienne, favorisant ainsi des solutions énergétiques durables.
En analysant les données historiques et en générant des simulations, les décideurs politiques peuvent faire des choix plus éclairés et fondés sur des données probantes pour l’amélioration de la société. Ces mêmes outils peuvent aider non seulement les décideurs politiques mais aussi les organisations de la société civile à générer des visualisations de données ou à résumer des informations sur les préférences des citoyens. Cela peut aider à produire un contenu plus informatif et plus opportun sur les préférences des citoyens et l’état des questions clés, comme le nombre de sans-abri.
L’IAGen peut être utilisée de manière à avoir un impact favorable sur l’environnement. Par exemple, elle peut être utilisée dans des domaines tels que l’architecture et la conception de produits pour optimiser les conceptions en termes d’efficacité. Elle peut servir à optimiser les processus dans l’industrie de l’énergie qui peuvent améliorer l’efficacité énergétique. L’IAGen peut également être utilisée dans le domaine de la logistique, où elle peut optimiser les itinéraires et les horaires, réduisant ainsi la consommation de carburant et les émissions.
Risques pour la démocratie
Pour exploiter le potentiel de l’IAGen au service de la démocratie et de l’espace civique, il est nécessaire d’adopter une approche équilibrée qui tienne compte des préoccupations éthiques, favorise la transparence, promeuve un développement technologique inclusif et engage de multiples parties prenantes. La collaboration entre les chercheurs, les décideurs politiques, la société civile et les développeurs de technologies peut aider à garantir que l’IAGen contribue positivement aux processus démocratiques et à l’engagement civique. La capacité à générer de grands volumes de contenu crédible peut créer des opportunités pour les décideurs politiques et les citoyens de se connecter les uns aux autres – mais ces mêmes capacités des modèles avancés d’IAGen créent également des risques potentiels.
Mésinformation en ligneMalgré les améliorations de l’IAGen, les modèles continuent de faire des erreurs tout en produisant des résultats convaincants, tels que des faits ou des histoires qui semblent plausibles mais incorrects. Si, dans de nombreux cas, ces erreurs sont bénignes – comme une interrogation scientifique sur l’âge de l’univers -, dans d’autres cas, les conséquences sont déstabilisantes sur le plan politique ou sociétal.
Étant donné que l’IAGen est orientée vers le public, les individus peuvent utiliser ces technologies sans en comprendre les limites. Ils pourraient alors, par inadvertance, diffuser des mésinformations à partir d’une réponse inexacte à une question sur la politique ou l’histoire, par exemple une déclaration inexacte sur un dirigeant politique qui finirait par enflammer un environnement politique déjà acrimonieux. La diffusion de mésinformation générées par l’IA qui inondent l’écosystème de l’information risque de saper la confiance dans l’écosystème de l’information dans son ensemble, amenant les gens à être sceptiques à l’égard de tous les faits et à se conformer aux croyances de leurs cercles sociaux. La diffusion d’informations peut amener les membres de la société à croire des choses fausses sur les candidats politiques, les procédures électorales ou les guerres.
Les exemples d’IAGen générant de la désinformation ne comprennent pas seulement des textes, mais aussi des « hypertrucages ». Si les hypertrucages ont des applications potentielles bienveillantes, comme le divertissement ou les effets spéciaux, ils peuvent aussi être utilisés à mauvais escient pour créer des vidéos très réalistes qui diffusent de fausses informations ou des événements fabriqués de toutes pièces, de sorte qu’il est difficile pour les spectateurs de faire la distinction entre le faux et le vrai contenu, ce qui peut entraîner la diffusion de mésinformation et éroder la confiance dans les médias. Dans le même ordre d’idées, ils peuvent être utilisés à des fins de manipulation politique, c’est-à-dire que des vidéos de politiciens ou de personnalités publiques sont modifiées pour leur faire dire ou faire des choses susceptibles de les diffamer, de nuire à leur réputation ou d’influencer l’opinion publique.
L’IAGen rend plus efficace la production et l’amplification de la désinformation, créée intentionnellement dans le but d’induire un lecteur en erreur, parce qu’elle peut produire en grande quantité des informations inexactes apparemment originales et crédibles. Aucun des récits ou commentaires ne se répéterait nécessairement, ce qui pourrait conduire à un récit encore plus crédible. Les campagnes de désinformation étrangères ont souvent été identifiées sur la base de fautes d’orthographe ou de grammaire, mais la capacité d’utiliser ces nouvelles technologies d’IAGen signifie la création efficace de contenu à consonance naturelle qui peut tromper les filtres habituels qu’une plate-forme pourrait utiliser pour identifier les campagnes de désinformation à grande échelle. L’IAGen pourrait également faire proliférer des robots sociaux qui ne se distinguent pas des humains et qui peuvent micro-cibler les individus en leur diffusant de la désinformation de manière personnalisée.
Les technologies de l’IAGen étant accessibles au public et faciles à utiliser, elles peuvent être utilisées pour manipuler non seulement le grand public, mais aussi les élites gouvernementales à différents niveaux. Les leaders politiques sont censés répondre aux préoccupations de leurs administrés, comme en témoignent les communications telles que les courriels qui révèlent l’opinion et le sentiment du public. Mais que se passerait-il si un acteur malveillant utilisait ChatGPT ou un autre modèle d’IAGen pour créer des volumes massifs de contenu de plaidoyer et les distribuer aux leaders politiques comme s’ils provenaient de vrais citoyens ? Il s’agirait d’une forme de contrefaçon d’opinion, une pratique trompeuse qui masque la source du contenu dans le but de donner l’impression d’un soutien populaire. Les recherches montrent que les élus américains sont sensibles à ces attaques. Les leaders pourraient bien laisser ce volume de contenu influencer leur agenda politique, en adoptant des lois ou en créant des instances administratives en réponse à l’apparente vague de soutien qui, en fait, a été fabrique par la capacité à générer de grands volumes de contenu à consonance crédible.
L’IAGen soulève également des problèmes de discrimination et de biais. Si les données d’apprentissage utilisées pour créer le modèle génératif contiennent des informations biaisées ou discriminatoires, le modèle produira des résultats biaisés ou offensants. Cela pourrait perpétuer des stéréotypes nuisibles et contribuer à la violation de la vie privée de certains groupes. Si un modèle d’IAGen est entraîné sur un jeu de données contenant des modèles de langage biaisés, il peut produire un texte qui renforce les stéréotypes de genre. Par exemple, il peut associer certaines professions ou certains rôles à un sexe particulier, même s’il n’y a pas de lien intrinsèque. Si un modèle d’IAGen est entraîné sur un jeu de données dont la représentation raciale ou ethnique est biaisée, il peut produire des images qui représentent involontairement certains groupes de manière négative ou stéréotypée. Ces modèles peuvent également, s’ils sont entraînés sur des jeux de données biaisés ou discriminatoires, produire des contenus qui ne tiennent pas compte des spécificités culturelles ou qui utilisent des termes péjoratifs. L’IAGen texte-image déforme les caractéristiques d’une « femme noire » de manière très fréquente, ce qui est préjudiciable aux groupes mal représentés. La cause en est la surreprésentation des groupes non noirs dans les jeux de données d’apprentissage. L’une des solutions consiste à disposer de jeux de données plus équilibrés et diversifiés, au lieu de se contenter de données occidentales et anglophones, qui contiendraient des préjugés occidentaux et en créeraient d’autres en raison de l’absence d’autres perspectives et d’autres langues. Une autre solution consiste à entraîner le modèle de manière à ce que les utilisateurs ne puissent pas le « pirater» pour qu’il diffuse des contenus racistes ou déplacés.
Cependant, la question des préjugés va au-delà des données d’apprentissage ouvertement racistes ou sexistes. Les modèles d’IA tirent des conclusions à partir de points de données ; ainsi, un modèle d’IA pourrait examiner les données relatives à l’embauche et constater que le groupe démographique qui a le mieux réussi à se faire embaucher dans une entreprise technologique est celui des hommes blancs, et en conclure que les hommes blancs sont les plus qualifiés pour travailler dans une entreprise technologique, bien qu’en réalité la raison pour laquelle les hommes blancs réussissent mieux est qu’ils ne sont pas confrontés aux mêmes obstacles structurels qui affectent d’autres groupes démographiques, tels que l’impossibilité de s’offrir un diplôme technique, le sexisme dans les cours ou le racisme dans le service d’embauche.
L’IAGen soulève plusieurs questions relatives à la protection de la vie privée. L’une d’elles est que les jeux de données peuvent contenir des informations sensibles ou personnelles. Si ce contenu n’est pas correctement anonymisé ou protégé, des informations personnelles peuvent être exposées ou utilisées à mauvais escient. Les résultats de l’IAGen étant censés être réalistes, le contenu généré qui ressemble à des personnes réelles pourrait être utilisé pour ré-identifier des personnes dont les données devaient être rendues anonymes, ce qui porterait également atteinte à la protection de la vie privée. En outre, au cours du processus d’apprentissage, les modèles d’IAGen peuvent apprendre et mémoriser par inadvertance des parties de leurs données d’apprentissage, y compris des informations sensibles ou privées. Cela peut entraîner des fuites de données lors de la création de nouveaux contenus. Les décideurs politiques et les plates-formes d’IAGen elles-mêmes n’ont pas encore résolu la question de la protection de la vie privée dans les jeux de données, les résultats, voire les invites elles-mêmes, qui peuvent contenir des données sensibles ou refléter les intentions d’un utilisateur d’une manière qui pourrait être préjudiciable si elle n’était pas sécurisée.
L’une des préoccupations fondamentales concernant l’IAGen est de savoir qui détient les droits d’auteur sur le travail créé par l’IAGen. La loi sur le droit d’auteur attribue la paternité et la propriété aux créateurs humains. Toutefois, dans le cas des contenus générés par l’IA, la détermination de la paternité, pierre angulaire du droit d’auteur, devient un défi. Personne ne peut dire si le créateur doit être le programmeur, l’utilisateur, le système d’IA lui-même ou une combinaison des deux. Les systèmes d’IA apprennent à partir de contenus existants protégés par le droit d’auteur pour générer de nouvelles œuvres qui pourraient ressembler à des contenus existants protégés par le droit d’auteur. Cela pose le problème de savoir si le contenu généré par l’IA peut être considéré comme une œuvre dérivée et donc porter atteinte aux droits du détenteur du droit d’auteur original ou si l’utilisation de l’IAGen serait considérée comme un usage loyal, qui permet une utilisation limitée du matériel protégé par le droit d’auteur sans l’autorisation du détenteur du droit d’auteur. La technologie étant encore récente, les cadres juridiques permettant de juger de l’utilisation équitable par rapport à la violation des droits d’auteur sont encore en évolution et peuvent varier en fonction des juridictions et de ses cultures juridiques. Au fur et à mesure que ce corpus législatif se développe, il devrait trouver un équilibre entre l’innovation et le traitement équitable des créateurs, des utilisateurs et des développeurs de systèmes d’IA.
L’apprentissage des modèles d’IAGen ainsi que le stockage et la transmission des données utilisent d’importantes ressources informatiques, souvent avec du matériel qui consomme de l’énergie pouvant contribuer aux émissions de carbone s’il n’est pas alimenté par des sources d’énergie renouvelables. Ces impacts peuvent être atténués en partie par l’utilisation d’énergies renouvelables et par l’optimisation des algorithmes afin de réduire les exigences informatiques.
Bien que l’accès aux outils de l’IAGen soit de plus en plus répandu, l’émergence de la technologie risque d’accroître la fracture numérique entre ceux qui ont accès à la technologie et ceux qui n’y ont pas accès. Il y a plusieurs raisons pour lesquelles l’inégalité d’accès – et ses conséquences – peuvent être particulièrement pertinentes dans le cas de l’IAGen :
- La puissance de calcul requise est énorme, ce qui peut mettre à rude épreuve l’infrastructure des pays qui ne disposent pas d’une alimentation électrique, d’un accès à l’Internet, d’un stockage de données ou d’un système informatique en Cloud adéquats.
- Les pays à revenu faible et intermédiaire (PRFI) peuvent ne pas disposer du vivier de talents de haute technologie nécessaire à l’innovation et à la mise en œuvre de l’IA. Selon un rapport, l’ensemble du continent africain compte 700 000 développeurs de logiciels, contre 630 000 en Californie. Ce problème est exacerbé par le fait qu’une fois qualifiés, les développeurs des PRFI partent souvent vers des destinations où ils peuvent monnayer davantage leur savoir-faire.
- Les modèles grand public tels que ChatGPT ont été entraînés dans une poignée de langues, dont l’anglais, l’espagnol, l’allemand et le chinois, ce qui signifie que les personnes cherchant à utiliser l’IAGen dans ces langues ont accès à des avantages dont ne disposent pas les locuteurs du swahili, par exemple, sans parler des dialectes locaux.
- La localisation de l’IAGen nécessite de grandes quantités de données provenant d’un contexte particulier, et les environnements à faibles ressources s’appuient souvent sur des modèles développés par de grandes entreprises technologiques basées aux États-Unis ou en Chine.
Le résultat final pourrait être la perte d’autonomie des groupes marginalisés qui ont moins de possibilités et de moyens de partager leurs histoires et leurs points de vue par le biais d’un contenu généré par l’IA. Étant donné que ces technologies peuvent améliorer les perspectives économiques d’un individu, un accès inégal à l’IAGen peut à son tour accroître les inégalités économiques, car ceux qui y ont accès sont en mesure de s’engager plus efficacement dans l’expression créative, la génération de contenu et l’innovation commerciale.
Questions
Si vous avez un projet et envisagez d’utiliser l’IAGen, posez-vous les questions suivantes :
-
Existe-t-il des cas où les interactions individuelles entre les personnes pourraient être plus efficaces, plus empathiques et même plus efficientes que l’utilisation de l’IA dans la communication ?
-
Quelles problèmes éthiques – qu’ils soient liés à des préjugés ou à la protection de la vie privée – l’utilisation de l’IAGen peut-elle susciter ? Peut-on les atténuer ?
-
Les sources locales de données et de talents peuvent-elles servir à créer une IAGen contextualisée localement ?
-
Existe-t-il des mesures juridiques, réglementaires ou de sécurité qui permettront de se prémunir contre les utilisations abusives de l’IAGen et de protéger les populations qui pourraient être vulnérables à ces utilisations abusives ?
-
Les informations sensibles ou exclusives peuvent-elles être protégées dans le processus de développement des jeux de données qui servent de données d’apprentissage aux modèles d’IAGen ?
-
De quelle manière la technologie de l’IAGen peut-elle combler la fracture numérique et accroître l’accès au numérique dans une société dépendante de la technologie (ou dans une société qui en devient de plus en plus dépendante) ? Comment pouvons-nous atténuer la tendance des nouvelles technologies de l’IAGen à élargir la fracture numérique ?
-
Existe-t-il des formes d’alphabétisation numérique pour les membres de la société, de la société civile ou d’une classe politique qui peuvent atténuer les risques liés aux hypertrucages ou aux textes de mésinformation générés à grande échelle ?
-
Comment pouvez-vous atténuer les impacts environnementaux négatifs associés à l’utilisation de l’IAGen ?
-
L’IAGen peut-elle servir à adapter les approches éducatives, l’accès au gouvernement et à la société civile, et les opportunités d’innovation et de progrès économiques ?
-
Les données sur lesquelles votre modèle a été entraîné sont-elles exactes et représentatives de toutes les identités, y compris des groupes marginalisés ? Quels sont les biais inhérents à ce jeu de données ?
Études de cas
L’IAGen est apparue de manière généralisée et orientée vers le consommateur au cours du premier semestre 2023, ce qui limite le nombre d’études de cas dans le monde réel. Cette section consacrée aux études de cas comprend donc des cas où des formes de l’IAGen se sont avérées problématiques en termes de tromperie ou de mésinformation ; des façons dont l’IAGen peut vraisemblablement affecter tous les secteurs, y compris la démocratie, pour accroître l’efficacité et l’accès ; et des expériences ou des discussions sur les approches spécifiques des pays concernant les compromis entre vie privée et innovation.
Expériences de désinformation et de tromperieAu Gabon, un éventuel hypertrucage a joué un rôle important dans la politique du pays. Le Président aurait été victime d’un accident vasculaire cérébral et n’avait pas été vu en public pendant un moment. Le gouvernement a finalement publié une vidéo la veille du Nouvel An 2018 afin d’apaiser les inquiétudes concernant la santé du Président, mais les critiques ont suggéré que les clignements des yeux et les expressions faciales de la vidéo étaient inauthentiques et qu’il s’agissait d’un « hypertrucage ». Les rumeurs selon lesquelles la vidéo n’était pas authentique ont proliféré, ce qui a amené beaucoup de gens à conclure que le président n’était pas en bonne santé, entraînant une tentative de coup d’État, car il se disait que la capacité du Président à résister à la tentative de renversement s’en trouverait affaiblie. Cet exemple montre les graves conséquences d’une perte de confiance dans l’environnement informationnel.
En mars 2023, une image d’IAGen du Pape vêtu d’un manteau Balenciaga est devenue virale sur l’Internet, trompant les lecteurs en raison de la ressemblance entre l’image et le Pape. Quelques mois auparavant, Balenciaga avait dû faire face à des réactions négatives en raison d’une campagne publicitaire qui mettait en scène des enfants harnachés et asservis. Le Pape, qui portait apparemment des vêtements Balenciaga, a alors laissé entendre que lui-même et l’Église catholique adhéraient à ces pratiques. Tout le monde sur l’Internet a finalement conclu qu’il s’agissait d’un hypertrucage après avoir identifié des signes révélateurs tels qu’une tasse de café floue et des problèmes de résolution au niveau de la paupière du Pape. Néanmoins, l’incident a illustré la facilité avec laquelle ces images peuvent être générées et tromper les lecteurs. Elle a également illustré la manière dont les réputations pouvaient être entachées par des « hypertrucages ».
En septembre 2023, la Microsoft Threat Initiative a publié un rapport faisant état de nombreux cas d’opérations d’influence en ligne. Avant les élections de 2022, Microsoft a identifié des comptes de médias sociaux affiliés au Parti communiste chinois (PCC) qui se faisaient passer pour des électeurs américains, répondant aux commentaires afin d’influencer les opinions par l’échange et la persuasion. En 2023, Microsoft a ensuite observé l’utilisation de visuels créés par l’IA qui présentaient des images américaines telles que la Statue de la Liberté sous un trait négatif. Ces images présentaient les caractéristiques de l’IA, comme le mauvais nombre de doigts sur une main, mais elles n’en étaient pas moins provocatrices et convaincantes. Au début de l’année 2023, Meta a également constaté que le PCC s’était engagé dans une opération d’influence en publiant des commentaires critiques à l’égard de la politique étrangère américaine, que Meta a pu identifier grâce aux types de fautes d’orthographe et de grammaire combinés à l’heure qu’il faisait (heure de Chine plutôt que des États-Unis).
Au fur et à mesure que les outils d’IAGen s’améliorent, ils deviendront encore plus efficaces dans ces campagnes d’influence en ligne. D’autre part, les applications affichant des résultats positifs deviendront également plus efficaces. L’IAGen, par exemple, interviendra de plus en plus pour combler les lacunes des ressources gouvernementales. On estime que quatre milliards de personnes n’ont pas accès aux services de santé de base, l’un des principaux obstacles étant le faible nombre de prestataires de soins de santé. Bien que l’IAGen ne remplace pas l’accès direct à un prestataire de soins de santé, elle peut au moins combler certaines lacunes en matière d’accès dans certains contextes. chatbot, Ada Health est un “a href=”https://ieeexplore-ieee-org.proxy.library.cornell.edu/stamp/stamp.jsp?tp=&arnumber=10124013″ target=”_blank” rel=”noopener”>robot conversationnel de santé alimenté par OpenAI et peut correspondre avec des personnes sur leurs symptômes. ChatGPT a démontré sa capacité à passer des examens de qualification médicale et ne devrait pas être utilisé pour remplacer un médecin, mais, dans des environnements où les ressources sont limitées, il pourrait au moins fournir un dépistage initial, ce qui permettrait d’économiser des coûts, du temps et des ressources. Dans le même temps, des outils similaires peuvent être utilisés dans le domaine de la santé mentale. Le Forum économique mondial a indiqué en 2021 qu’on estime à 100 millions le nombre de personnes souffrant de dépression clinique en Afrique, mais qu’il n’y a que 1,4 prestataires de soins de santé pour 100 000 habitants, où la moyenne mondiale prévoit 9 prestataires pour 100 000 habitants. Les personnes qui ont besoin de soins et qui n’ont pas de meilleures options s’en remettent de plus en plus aux robots conversationnels de santé mentale jusqu’à ce qu’une approche plus complète puisse être mise en œuvre, car même si le niveau de soins qu’ils peuvent fournir est limité, c’est mieux que rien. Les ressources basées sur l’IAGen ne sont pas exemptes de défis et de problèmes potentiels en matière de protection de la vie privée, mais elles offrent en plus des solutions inadéquates. Les sociétés et les individus devront déterminer si ces outils sont supérieurs à l’alternative, même s’ils sont limités en termes de ressources.
D’autres scénarios futurs prévoient l’utilisation de l’IAGen pour accroître l’efficacité de l’action du gouvernement dans toute une série de tâches. L’un de ces scénarios est celui d’un bureaucrate formé à l’économie et chargé de travailler sur un document d’orientation relative à l’environnement. La personne commence à rédiger le document d’orientation, mais soumet ensuite la question à un outil d’IAGen, qui l’aide à rédiger une ébauche d’idées, lui rappelle les points qui ont été oubliés, identifie les principales lignes directrices juridiques internationales pertinentes et traduit ensuite la note en anglais en français. Un autre scénario concerne un citoyen qui essaie de savoir où voter, payer ses impôts, clarifier les procédures gouvernementales, donner un sens aux politiques pour ceux qui décident entre les candidats, ou expliquer certains concepts politiques. Ces scénarios sont déjà possibles et accessibles à tous les niveaux de la société et ne feront que se répandre à mesure que les individus se familiariseront avec la technologie. Toutefois, il est important que les utilisateurs comprennent les limites et la manière d’utiliser correctement la technologie afin d’éviter les situations dans lesquelles ils diffusent des mésinformations ou ne parviennent pas à trouver des informations exactes.
Dans un contexte électoral, l’IAGen peut aider à évaluer des aspects de la démocratie, tels que l’intégrité électorale. Le dépouillement manuel des votes, par exemple, prend du temps et est onéreux. Cependant, les nouveaux outils d’IA ont joué un rôle dans l’évaluation du degré d’irrégularité des élections. Des réseaux neuronaux ont été utilisés au Kenya pour « lire » les formulaires papier soumis au niveau local et énumérer le degré d’irrégularités électorales, puis les corréler avec les résultats électoraux afin de déterminer si ces irrégularités étaient le résultat d’une fraude ou d’une erreur humaine. Ces technologies peuvent en fait alléger la charge de travail des institutions électorales. À l’avenir, les progrès de l’IAGen permettront de visualiser les données afin d’alléger la charge cognitive des efforts déployés pour statuer sur l’intégrité électorale.
Des pays comme le Brésil se sont inquiétés des abus potentiels de l’IAGen. Après la sortie de ChatGPT en novembre 2022, le gouvernement brésilien a reçu un rapport détaillé, rédigé par des experts universitaires et juridiques ainsi que par des dirigeants d’entreprises et des membres d’un organisme national de surveillance de la protection des données, qui demandait instamment que ces technologies soient réglementées. Le rapport fait ressortir trois préoccupations majeures :
- Les droits des citoyens doivent être protégés en garantissant « la non-discrimination et la correction des préjugés discriminatoires directs, indirects, illégaux ou abusifs », ainsi que la clarté et la transparence quant à l’interaction des citoyens avec l’IA.
- Que le gouvernement catégorise les risques et informe les citoyens des risques potentiels. Sur la base de cette analyse, les secteurs à « haut risque » comprenaient les services essentiels, la vérification biométrique et le recrutement, et les secteurs à « risque excessif » comprenaient l’exploitation des personnes vulnérables et la notation sociale (un système qui suit le comportement des individus pour déterminer s’ils sont dignes de confiance et qui inscrit sur une liste noire ceux qui ont trop de démérites ou équivalents), deux pratiques qui devraient être examinées de près.
- Que le gouvernement prenne des mesures de gouvernance et des sanctions administratives, d’abord en déterminant comment les entreprises qui ne respectent pas la réglementation seraient pénalisées et ensuite en recommandant une pénalité de 2 % du chiffre d’affaires pour les infractions légères et l’équivalent de 9 millions de dollars américains pour les préjudices plus graves.
Au moment de la rédaction de cet article, en 2023, le gouvernement débattait des prochaines étapes, mais le rapport et les délibérations illustrent les préoccupations et les recommandations émises en ce qui concerne l’IAGen dans les pays du Sud.
En Inde, le gouvernement a abordé l’IA en général et l’IAGen en particulier sous un angle moins sceptique, ce qui met en lumière les différences dans la manière dont les gouvernements peuvent aborder ces technologies et le fondement de ces différences. En 2018, le gouvernement indien a proposé une stratégie nationale de l’IA, qui donne la priorité au développement de l’IA dans l’agriculture, l’éducation, les soins de santé, les villes intelligentes et la mobilité intelligente. En 2020, la stratégie nationale d’Intelligence artificielle a demandé que tous les systèmes soient transparents, responsables et impartiaux. En mars 2021, le gouvernement indien a annoncé qu’il utiliserait une réglementation « légère » et que le plus grand risque ne résidait pas dans l’IA mais dans le fait de ne pas saisir les opportunités qu’offre l’IA. L’Inde dispose d’un secteur de recherche et de développement technologique avancé prêt à tirer parti de l’IA. Selon le ministère de l’Électronique et des technologies de l’information, la progression de ce secteur est « importante et stratégique », même s’il a reconnu qu’il fallait mettre en place des politiques et des d’infrastructure pour lutter contre les préjugés, la discrimination et les problèmes d’éthique.
Références
Vous trouverez ci-dessous les ouvrages cités dans cette ressource.
- Borji, Ali, (2021). Pros and Cons of GAN Evaluation Measures: New Developments.
- Breland, Ali, (2019). The Bizarre and Terrifying Case of the “Deepfake” Video that Helped Bring an African Nation to the Brink, Mother Jones.
- Byman, Dan, et al., (2023). Deepfakes and International Conflict, Brookings Institution.
- Gondwe, Gregory, (2023). CHATGPT and the Global South: how are journalists in sub-Saharan Africa engaging with generative AI?
- Heikkila, Melissa, (2023). How OpenAI is trying to make ChatGPT safer and less biased, MIT Tech Review.
- Hutson, Matthew, (2023). Rules to keep AI in check: Nations carve different paths for tech regulation. Nature.
- Jungherr, Andreas, (2023) “Artificial Intelligence and Democracy: A Conceptual Framework,” Social Media and Society.
- Kreps, Sarah & Jakesch, Maurice, (2023). Can AI communication tools increase legislative responsiveness and trust in democratic institutions? Government Information Quarterly.
- Kreps, Sarah & Kriner, Doug, (2023). The potential impact of emerging technologies on democratic representation: Evidence from a field experiment. New Media and Society.
- Kshetri, Nir, (2023). ChatGPT in Developing Economies. IEEE Xplore.
- Microsoft, Seeing AI in New Languages.
- Phiri M, Munoriyarwa A., (2023). Health Chatbots in Africa: Scoping Review. J Med Internet Res.
- Porsdam Mann, Sebastian, et al., (2023). Generative Ai entails a credit-blame asymmetry. Nature Machine Intelligence.
- Trager, Robert F., et al., (2023). International Governance of Civilian AI: A Jurisdictional Certification Approach.
- Warner, Zach, et al., (2021). Hidden in plain sight? Irregularities on statutory forms and electoral fraud. Electoral Studies.
Ressources complémentaires
- Andrej Karpathy, Introduction to Large Language Models.
- Arguedas, A. R., & Simon, F. M., (2023). Automating Democracy: Generative AI, Journalism, and the Future of Democracy. Balliol Interdisciplinary Institute, University of Oxford.
- Bhaskar, Chakravorti, (2023). The AI Regulation Paradox. Foreign Policy.
- Schneier, Bruce & Sanders, Nathan, (2023). Six Ways that AI Could Change Politics. MIT Tech Review.
- Hogg, Luke, (2023). Artificial Intelligence Could Democratize Government.Tech Policy Press.
- Muggah, Robert & Szabó, Ilona, (2023). Artificial Intelligence Will Entrench Global Inequality. Foreign Policy.
- Kreps, Sarah & Kriner, Doug, (2023). How Generative AI Affects Democratic Engagement. Brookings Institution.
- Nvidia, What is Generative AI?
Related Technologies & Trends
Technologies et tendances

Les Principes pour le Développement Numérique
- Concevoir avec l’utilisateur
- Comprendre l’écosystème existant
- Concevoir pour le passage à l’échelle
- Être guidé par les données
- Utiliser des standards ouverts, des données ouvertes, des innovations ouvertes et des sources ouvertes
- Prendre en compte la vie privée et la sécurité